이번 포스트에서는 지난 4회에 걸쳐 익힌 Data Preparation 과정을 실습을 통해 익혀보겠습니다
태블로 데스크탑에서 데이터 정제를 위해 활용하는 기능은 크게 아래의 세 가지 정도라고 말씀드렸습니다
▪ 데이터 해석기
▪ 피벗
이와 함께 필요에 따라서 데이터 원본 필터를 적절히 사용하면, 성능 측면에서 더 나은 결과를 얻을 수 있다고 했지요
위의 기능들을 하나 하나씩 적용해보며, 그 용법을 되새겨보겠습니다 :D
첫번째, 데이터 해석기 (Data Interpreter)
오늘 실습에 활용할 데이터는 2018년 8월 기준 주민등록 인구 데이터입니다
행정안전부에서 매월 성/연령 기준으로 인구 데이터를 업데이트하고 있는데, 읍면동 레벨까지 데이터 확인이 가능합니다
(링크가 깨질 경우 구글에서 '주민등록 인구통계 행정안전부' 검색)
먼저 데이터셋을 살펴보겠습니다
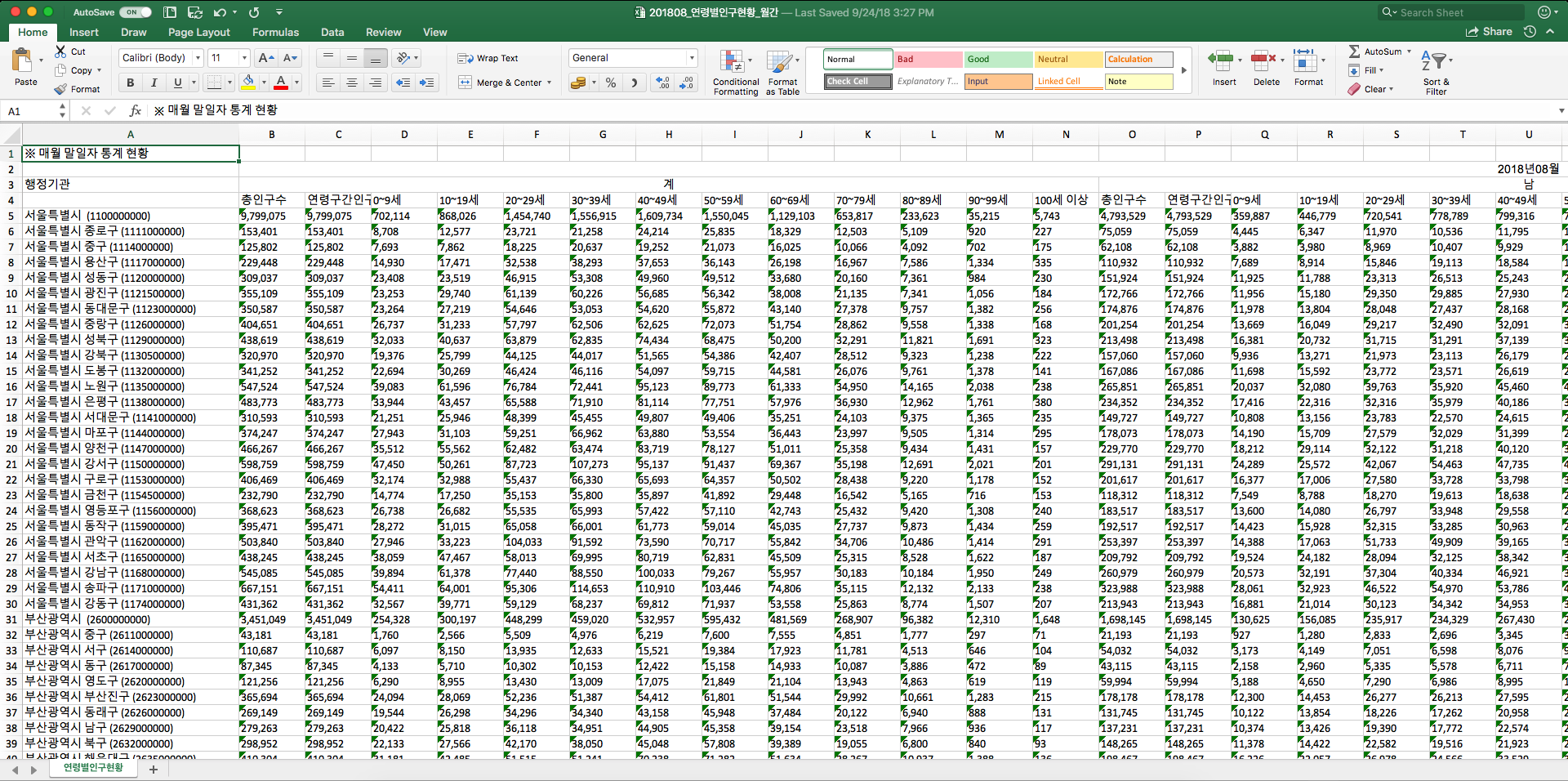
행에는 행정구역 정보가 들어가있습니다. 하나의 행정구역이 하나의 줄입니다
열에는 인구수 정보가 있는데, 먼저 계가 나오고, 다음으로는 남성이 보입니다. 위의 그림에서는 잘려서 보이지 않지만 옆에 여성도 있습니다
각 성별 아래에 나이가 10세 기준으로 나뉘어져 있습니다
연습하기 딱 좋은 데이터셋이 아닐 수 없습니다 :D
먼저 태블로로 불러들이겠습니다, 뿅
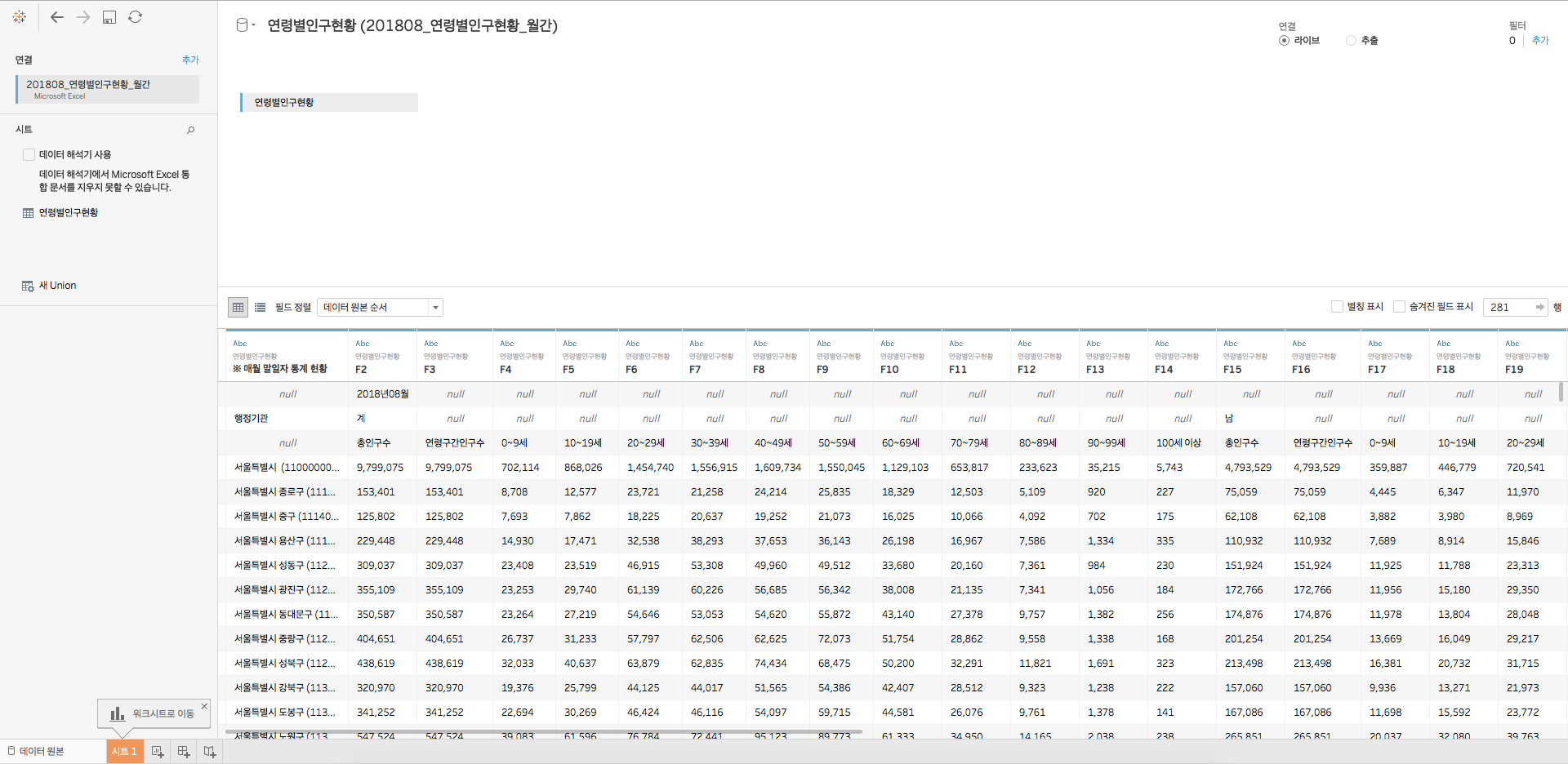
위의 그림에서 세번째 행이 컬럼명으로 인식되어야 하는데, 그러지 못하고 있군요
데이터 해석기는 병합된 셀을 해제하는 경우에도 유용하지만,
이처럼 불필요한 행으로 인해 컬럼명으로 인식되어야하는 행이 밑으로 몇 줄 내려와있을 때에도 매우 유용하게 사용할 수 있답니다
좌측 상단 체크박스를 클릭함으로써, 데이터 해석기를 실행시켜 보겠습니다
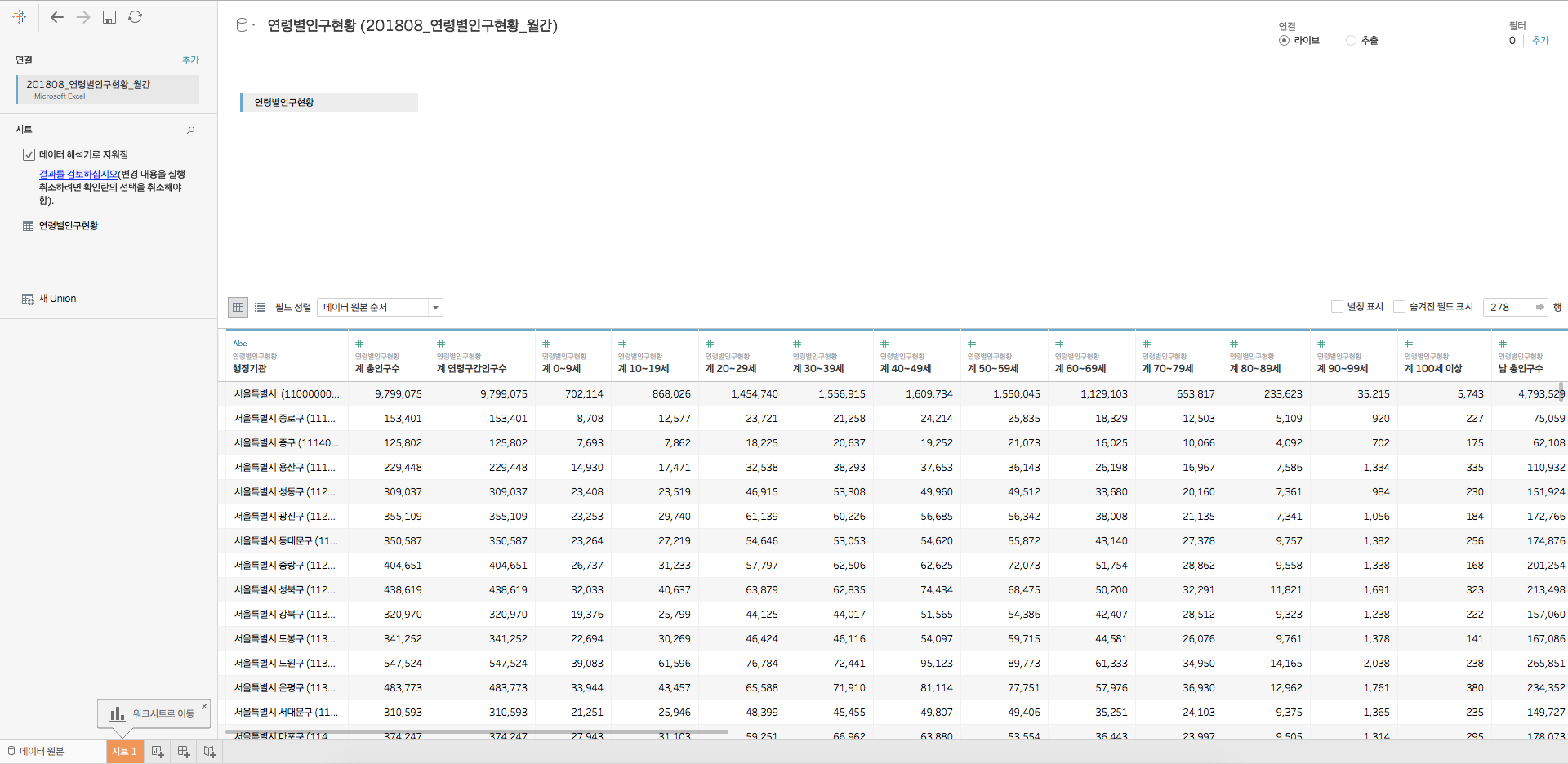
말끔하게 정리되었습니다
다만, 성별 정보와 연령 정보가 필드명에 함께 들어가있는데, 이 부분은 뒤쪽의 사용자 지정 분할을 통해 정리하도록하죠
다음은 성별에서 Level of Detail을 맞추는 작업을 해보겠습니다
성별은 남성과 여성으로 나뉘어지는데, 이 둘을 합치면 "계"가 되는 것이죠
남성과 여성으로 나뉘어져있는 데이터셋에 "계"가 들어가있으면 데이터의 Level of Detail이 맞지 않습니다
따라서 "계" 항목을 숨기도록 하겠습니다
시프트키를 이용하여 숨길 필드를 아래와 같이 한꺼번에 선택한 후 선택된 아무 필드명 위에서 마우스 우클릭, 숨기기를 누르면 됩니다

그러면 아래 그림과 같이 선택된 부분이 싹 숨김 처리됩니다
제일 왼쪽 행정기관, 남 총인구수부터 제일 오른쪽 여 100세 이상까지 나오고 있습니다
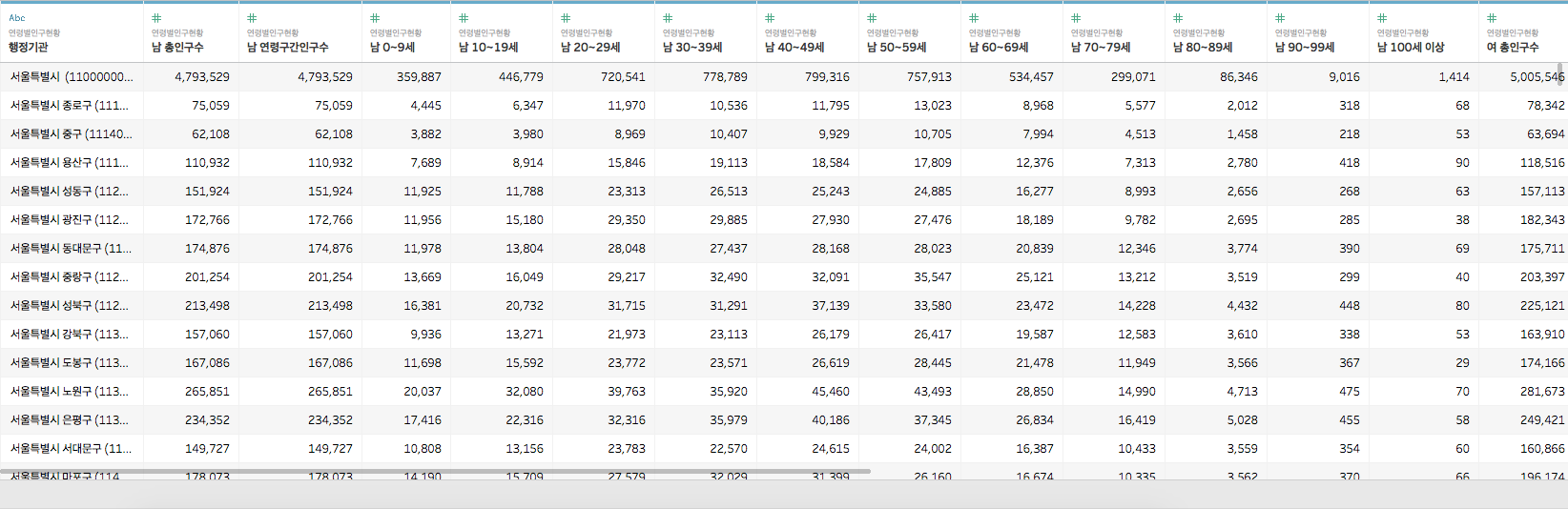
성별에서 "계"를 숨기면서 Level of Detail을 맞춰줬기 때문에,
이번에는 나이에서도 필요 없는 필드들을 숨기면서 데이터셋의 Level of Detail을 맞추어보도록 하겠습니다
연령은 0세부터 10세 단위로 구분되어 있고, 가장 높은 연령대 단위는 100세 이상입니다
따라서 총인구수와 연령구간인구수는 모든 연령대의 합산 인구수입니다, 성별에서 "계"와 같은 개념이죠
역시 숨겨보도록 하겠습니다
컨트롤키를 이용해서 남 총인구수, 남 연령구간인구수, 여 총인구수, 여 연령구간인구수,
네 개의 필드를 한꺼번에 선택한 후 아까와 동일한 방법으로 숨겨줍니다

이제는 아래의 그림처럼 데이터의 Level of Detail이 모두 동일하게 맞추어졌습니다
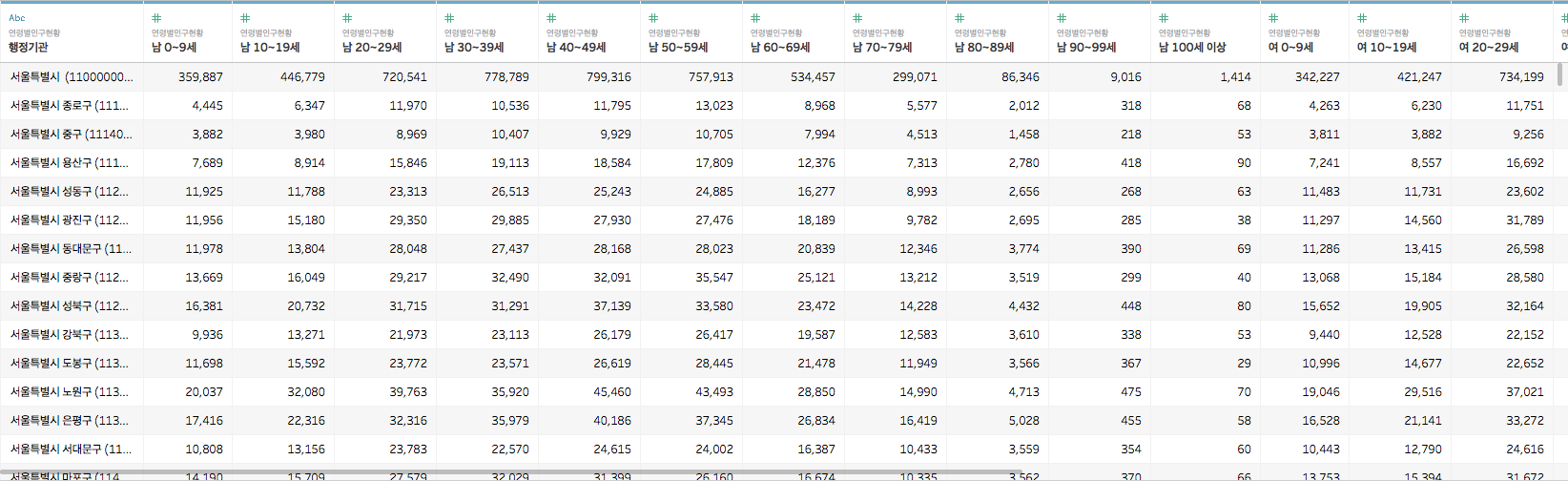
이제 다음 단계인 피벗으로 넘어갈 준비가 완료되었네요 :D
두번째, 피벗 (Pivot)
이제는 피벗을 쓸 차례입니다
옆으로 길게 늘어진 데이터를 아래로 길게 세우는 기능이죠
첫번째 컬럼 '남 0~9세' 부터 마지막 컬럼 '여 100세 이상' 까지 시프트키를 이용해서 한꺼번에 잡아준 후
필드명 위에서 우클릭, 피벗을 선택합니다

아래와 같이 데이터셋이 변형됩니다. 가로로 길게 나열되어있던 데이터셋이 세로로 길게 만들어졌습니다

이 단계에서 '피벗 필드명', '피벗 필드 값'과 같은 필드명을 바꾸어줄 필요는 없습니다
아직까지 모든 정제 과정이 끝난 것이 아니기 때문에, 필드명을 잡아주는 것은 제일 마지막 단계에서 진행하도록 하지요
세번째, 사용자 지정 분할 (Custom Split)
이제는 성별과 연령대를 구분해보겠습니다. 바로 사용자 지정 분할이 들어오는 지점이죠
피벗 필드명 위에서 마우스 우클릭하면, 사용자 지정 분할 선택이 가능합니다

그러면 대화상자가 나오면서, 어떤 구분자를 활용할래? 자르고 난 후 결과물은 어떤 것을 가지고 올래? 물어봅니다
성별과 연령대는 스페이스바 한 칸으로 띄어져있는 것으로 보입니다. 따라서 구분 기호 사용에는 스페이스바 한 칸을 입력합니다
스페이스바 한 칸을 기준으로 앞은 성별 뒤는 연령대 정보이니, 우리에게는 두 가지 정보 모두 필요합니다
따라서 분할 해제는 전체를 선택하겠습니다

확인을 누르면 아래 그림과 같은 결과가 나오네요
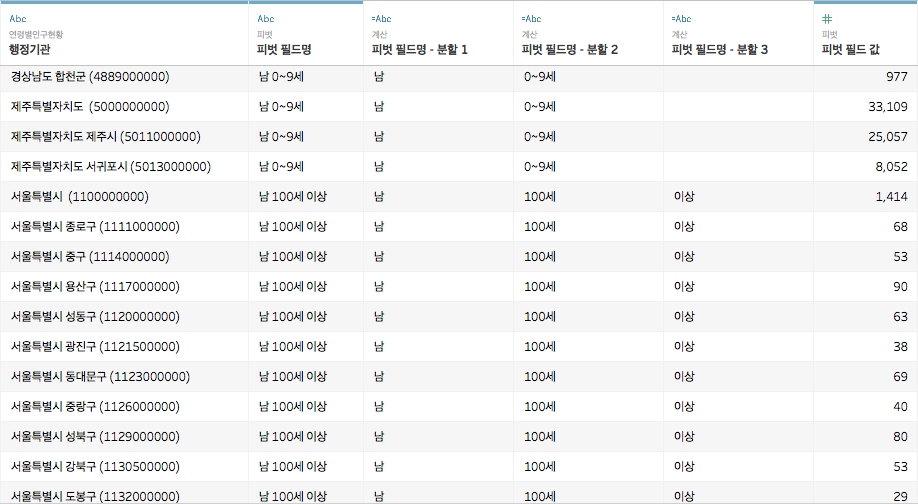
분할 1은 성별, 분할 2는 연령대인데, 분할 3이라는 것도 생겼습니다. 뭐죠?
마우스를 쭉 내리다보면 '100세 이상'이 '100세'와 '이상'으로 쪼개진 것을 확인할 수 있습니다
'100세'와 '이상' 사이에 스페이스바 한 칸이 있었던 것 같습니다
크게 불편함을 못느낀다면 분할 3은 숨김 처리해도 상관없지만, 100세와 이상을 꼭 붙여야겠다 싶으면 이런 방법이 가능합니다
'피벗 필드명 - 분할 2' 헤더 부분에서 마우스 우클릭하면, 계산된 필드 만들기를 선택할 수 있습니다
선택하게 되면 계산된 필드 만들기 창이 뜨고, 아래와 같이 입력하면 되겠죠

태블로에서 문자열(String) 필드는 + 기호만 사용하면 붙일 수 있습니다 (엑셀의 concatenate 기능과 동일하지만, 훨씬 간단하죠 :D)
특이한 점은 '분할 2'와 '분할 3' 사이에 공백 한 칸을 쌍따옴표를 활용해 넣어줬습니다, 두 필드를 붙이되 중간에 한 칸 띄우란 의미이죠
그리고 필드명은 '연령대'로 지어줬습니다
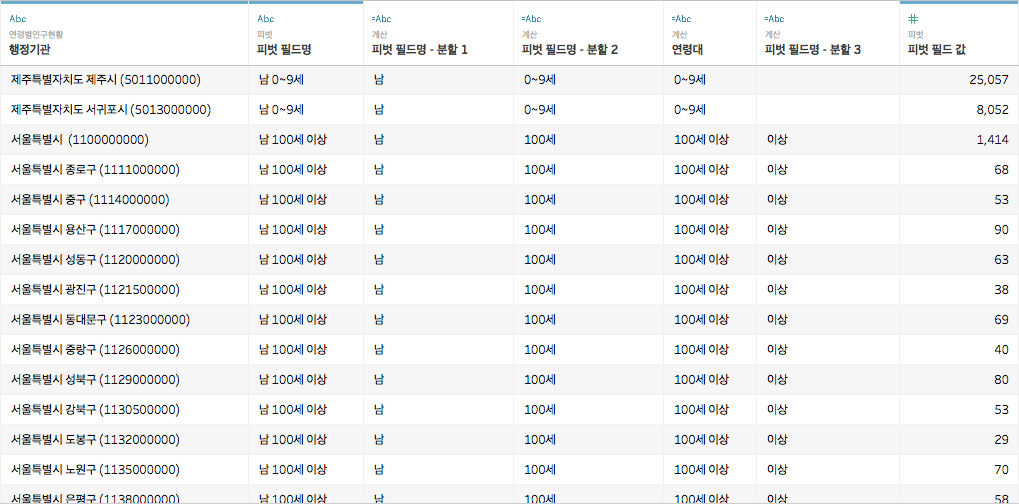
이제 불필요한 '피벗 필드명', '분할 2', '분할 3'을 숨김 처리하고,
'분할 1'의 필드명을 성별로, '피벗 필드 값'의 필드명을 인구수로 바꾸도록 하겠습니다
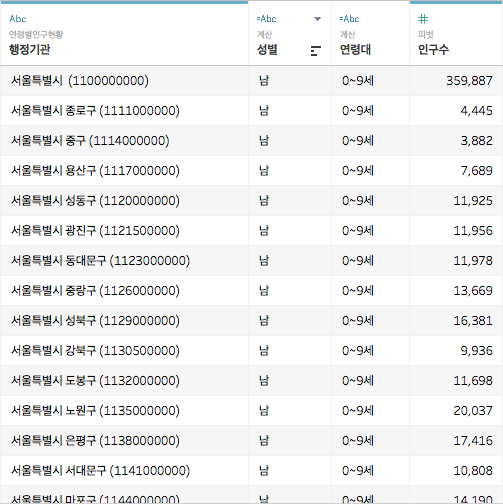
깔끔한 데이터셋이 만들어졌습니다만, 하지만 아직 끝이 아닙니다!?
경기도 부분을 한 번 살펴볼까요?
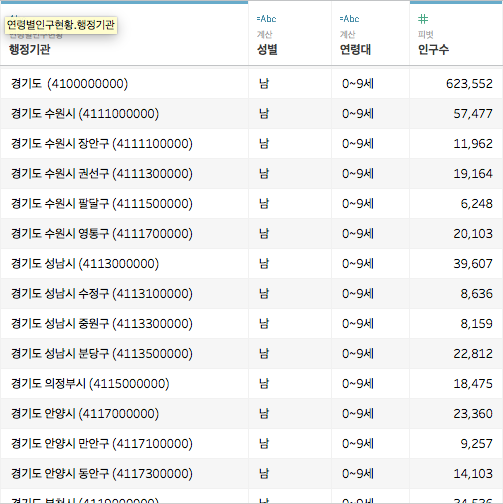
제일 위에 경기도가 나와있고, 다음은 경기도 수원시, 다음은 경기도 수원시 장안구입니다
행에 있는 행정기관의 Level of Detail이 맞지 않습니다
세 개의 행정구역 레벨이 혼재되어 있는데, 이를 맞춰주는 작업이 필요합니다
저기에 저렇게 섞여있으면, 실제 분석 시 인구수를 합계로 잡았을 때 인구수가 뻥튀기 되어 버립니다, 완전 망하는 것이지요 ㅠㅠ
먼저 ' (' (스페이스바 한 칸과 여는 괄호)를 구분자로 하여 뒤쪽의 행정기관 코드를 날려버리겠습니다
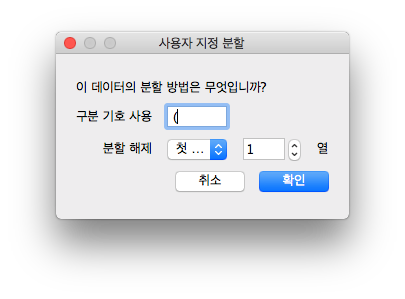
구분 기호 앞에 스페이스바 한 칸과 여는 괄호가 들어간 것을 확인할 수 있습니다
저 구분 기호를 기준으로 앞쪽에 있는 덩어리만 가지고오면 되므로, 첫 번째, 1열 선택하면 되겠습니다

위의 그림과 같이 '행정기관 - 분할 1'이 새롭게 생겼습니다
계속해서 이 필드를 스페이스바 한 칸을 구분자로 잘라보겠습니다.
'행정기관 - 분할 1'의 헤더 부분을 우클릭한 후 사용자 지정 분할을 눌러주면 되겠지요?
그리고 잘린 덩어리는 모두 가져와봅시다
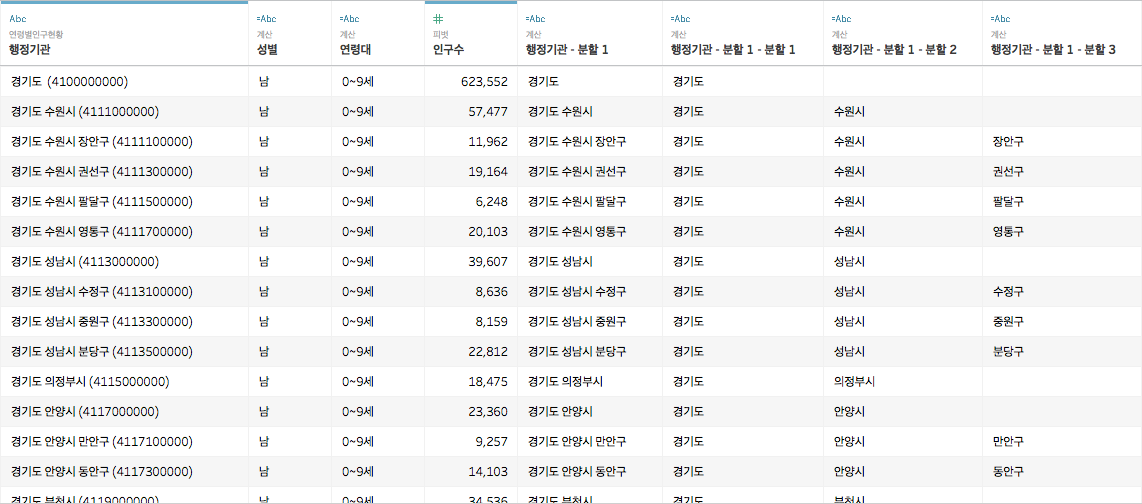
'행정기관' 필드와 '분할 1' 필드는 숨기고,
'분할 1-1'은 시도, '분할 1-2'는 시군구(자치구), '분할 1-3'은 시군구(일반구)로 이름을 바꾸어주겠습니다

여기서부터는 데이터의 활용 목적에 따라 시도만 있는 행을 날려버릴 수도 있고,
시군구(일반구)까지 드릴 다운되어있는 행을 필터링할 수도 있습니다
서울시, 경기도, 부산 등의 광역 지자체를 제외하려면,
데이터 원본 필터를 활용하여 시군구(자치구) 필드에서 빈 값(blank)만 제외하면 됩니다
시군구(일반구) 값이 붙어있는 행을 필터링하려면,
데이터 원본 필터에서 시군구(일반구) 필드의 빈 값(blank)만 살려두면 됩니다
(장안구, 권선구 등 무엇이든지 간에 값이 붙어 있는 행들을 날리면 되는 것이죠)
여기에서는 데이터 원본 필터 사용법을 복습하기 위해 광역 지자체 행만 제외해보겠습니다
화면 우측 상단에서 데이터 원본 필터 추가를 누르면 아래와 같은 대화창이 나옵니다
추가 버튼을 눌러주고 시군구(자치구)를 선택합니다
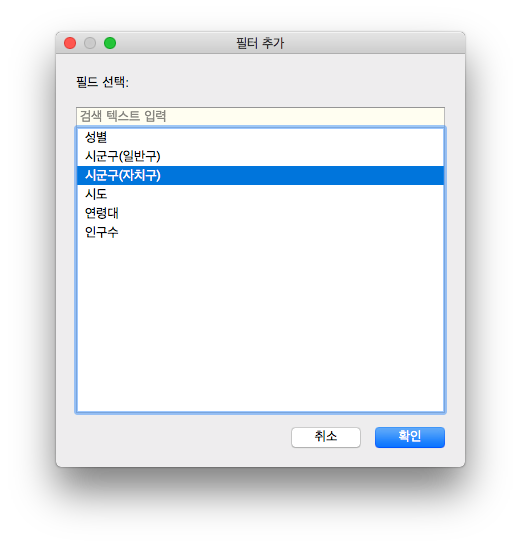
그러면 아래의 그림과 같이 시군구(자치구) 항목 중 선택할 수 있는 대화창이 뜹니다
오른쪽 하단의 제외 체크박스 클릭한 후 빈 칸(blank)을 선택합니다
시군구(자치구) 필드에서 빈 칸으로 되어있는 행은 제외하겠다는 의미입니다
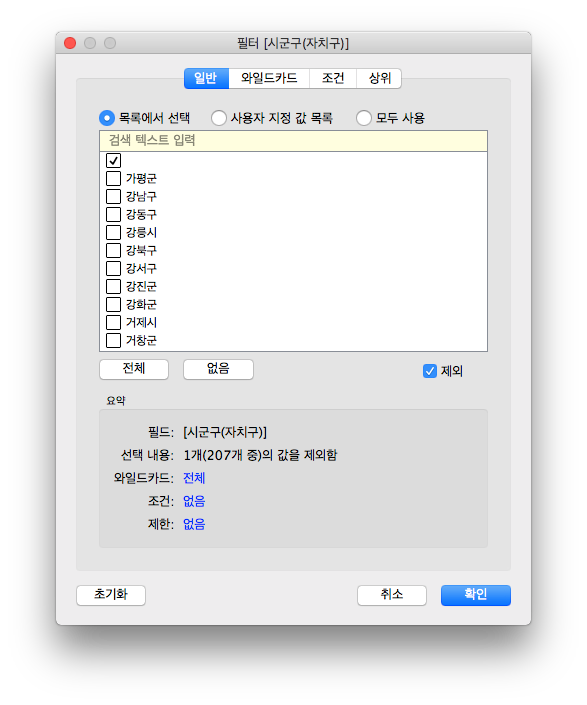
확인을 누르면 필터가 추가된 것을 확인할 수 있습니다
데이터를 살펴보면, 광역지자체 경기도가 제외된 것을 확인할 수 있죠
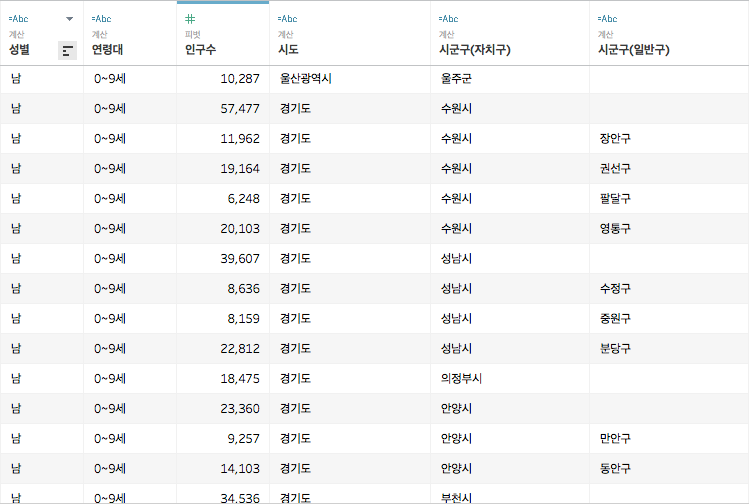
필요에 따라 데이터 원본 필터를 활용하여 불필요한 데이터를 제외하는 것까지 연습해보았습니다 :D
위의 데이터 또한 여전히 인구수가 뻥튀기될 위험을 내재하고 있습니다
수원시 장안구, 권선구, 팔달구, 영통구의 인구수 합계가 결국 수원시의 인구수(57,477)과 같기 때문이죠
이런 데이터의 구조를 미리 알고, 실제 화면을 만드는 과정에서 필터를 적절하게 사용하여 정확한 숫자를 만들어줘야 합니다
데이터 분석의 성패는 데이터 정제에 달려있다?!
데이터 정제는 본질적으로 힘들고 지난한 과정을 수반합니다
아래의 그림은 데이터를 분석하는 과정에서 즐거움의 정도를 재미있게 표현한 그래프입니다
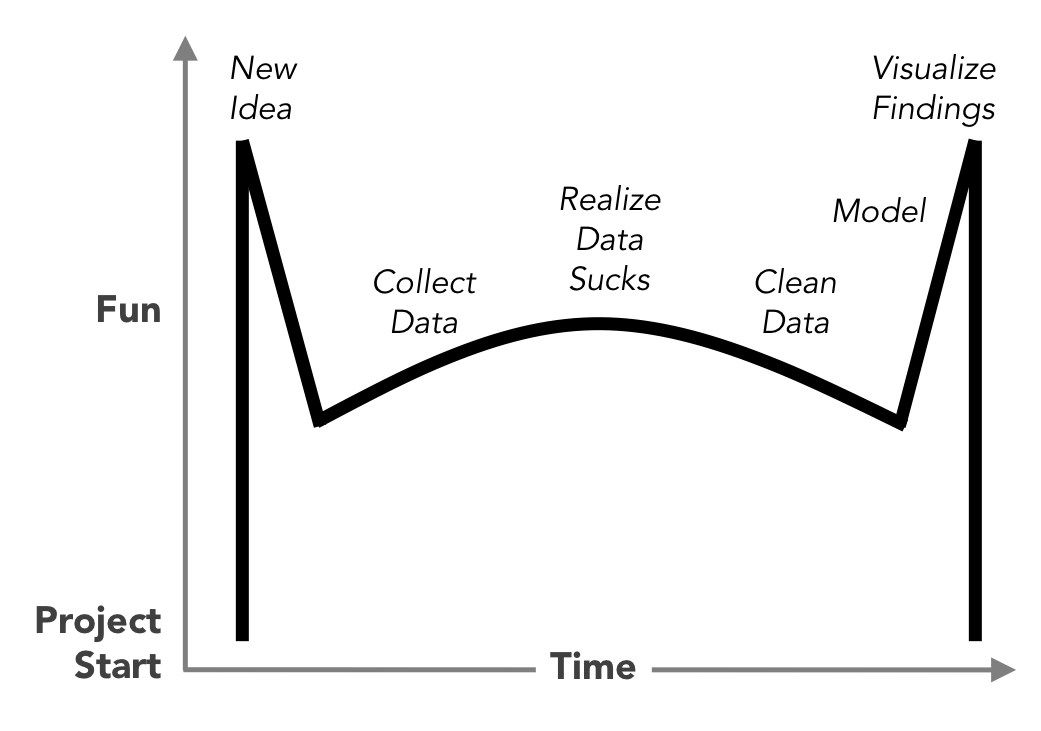
데이터가 쓰레기 같다는 것을 인식한 후 클린징하는 작업에서 계속 재미가 떨어지는 곡선이 보이죠
웃고 넘긴 차트(배트맨 차트라나 뭐라나)이지만, 꽤나 들어맞는다 싶었습니다
지난한 과정임에도, 분석의 성패가 여기에서 갈리기에, 간과할 수 없는 매우 중요한 부분입니다
다음 포스트에서는 Data Preparation의 마지막 이슈, Custom SQL을 한 번 정리해보겠습니다 :D

'v3 | Tableau Deep Dive' 카테고리의 다른 글
| [3]-1. 조인 (1) (1) | 2019.10.06 |
|---|---|
| [2]-6. 사용자 지정 SQL (3) | 2019.10.06 |
| [2]-4. 데이터 원본 필터 (1) | 2019.10.05 |
| [2]-3. 사용자 지정 분할 (1) | 2019.10.04 |
| [2]-2. 피벗 (1) | 2019.10.03 |



